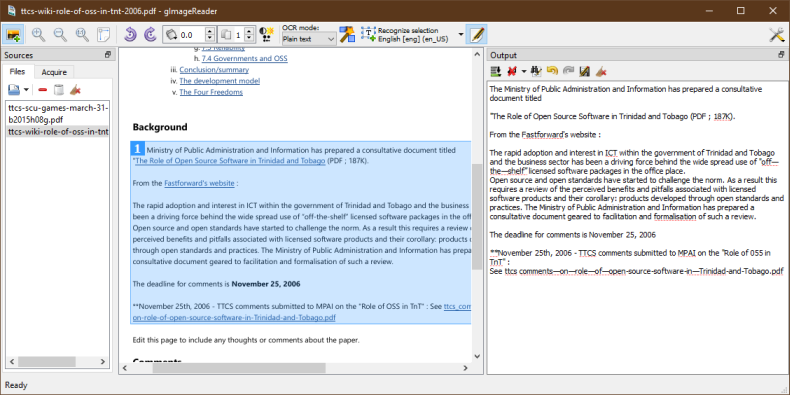
gImageReader can recognize text from images and PDFs to editable text (known as Optical Character Recogonition or OCR for short).
On loading a source image or PDF, you can select which part of the image or PDF you want text to be recognized.
gImageReader uses the Tesseract Open Source OCR Engine to recognize the text. You can choose to recognize to either plain text or in hOCR format.
The recognized text is shown next to the image and you can futher edit the text for saving or copying to the clipboard.